소개
머신러닝 기법은 우리의 세계관을 변화시키고 있으며 그것들은 우리의 일상생활의 모든 측면에 영향을 미치고 있다. 따라서 머신러닝은 정보보안에 큰 역할을 하고 있다. 이 모듈에서는 머신러닝 기법의 기본 원리를 탐구할 뿐만 아니라 최첨단 기법, 프로그래밍 라이브러리 및 공개 사용 가능한 데이터셋을 사용하여 처음부터 실제 침입 탐지 시스템을 구축하는 방법을 배우기 위한 실제 경험을 살펴보게 된다.
이 모듈에는 다음이 포함된다.
- 머신러닝 모델
- 기계 학습 프로젝트를 구축하는 데 필요한 단계
- 기계 학습 모델 평가 방법
- 가장 유용한 데이터 과학 및 기계 학습 라이브러리
- 인공신경망과 딥러닝
- 머신러닝 기법을 이용한 차세대 침입 탐지 시스템.
인공지능
인공지능은 컴퓨터 프로그램이 사람처럼 행동하도록 만드는 기술이고, 그것은 인지, 학습, 이해, 그리고 아는 것을 의미한다. AI는 컴퓨터 과학, 신경 과학, 심리학 등과 같은 많은 분야들이 관련되어 있다.

머신러닝 모델
머신러닝(machine learning)은 주어진 데이터와 예로부터 배우는 알고리즘의 생성과 연구다. 인공지능에 대한 특별한 접근법이다.Tom M. Mitchell (미국 컴퓨터 과학자 )은 머신러닝을 "컴퓨터 프로그램은 어떤 과업 T와 성능 측정 P에 의해 측정된 T에서의 업무 수행이 경험 E로 향상되면 경험 E로부터 배운다고 한다"라고 정의한다. 머신러닝에서 우리는 감독, 준슈퍼vi 4가지 주요 모델을 가지고 있다.침착하고, 감시되지 않고, 강화되었다.
I. 감독 학습: 입력과 출력 변수가 있다면 감독되는 학습이다. 이 경우에는 입력과 출력 사이의 기능만 매핑하면 된다. 감독 학습은 분류와 회귀라는 두 가지 다른 하위 범주로 나눌 수 있다. - 분류:출력이 범주형 변수인 경우 - 회귀 분석: 출력 변수가 연속형 값인 경우
감독되는 학습 알고리즘을 살펴봅시다.
- 순진한 베이즈: 이 분류 알고리즘은 베이즈족의 정리에 기초한다.

- 의사결정 나무: 나무와 같은 그래프 덕분에 가능한 출력을 예측하는 머신러닝 알고리즘으로, 데이터 전체를 루트 노드로 표현하고 최종 리프(Leaf)를 터미널 노드라고 한다.분할 가능한 노드를 의사결정 노드라고 한다.
- Support Vector Machine: 다차원 공간에 표현되는 데이터의 분리된 하이퍼 평면을 식별하는 데 사용되는 이진 분류자.따라서 그러한 하이퍼 평면은 단순한 선이 필요하지 않다.

II. 반 감독: 이 모델은 라벨이 부착된 데이터와 라벨이 부착되지 않은 데이터를 모두 포함하는 동안 완전히 감독되지 않는다. 이 모델은 학습 정확도를 높이기 위해 일반적으로 사용된다. - 감독되지 않음: 우리가 출력 변수에 대한 정보를 가지고 있지 않다면 그것은 감독되지 않은 학습이다.그 모델은 라벨이 부착되지 않은 데이터로 완전히 훈련되었다.군집화는 가장 잘 알려진 감독되지 않은 기술 중 하나이다.

III. 강화: 이 모델에서는 환경(보상)의 피드백을 바탕으로 에이전트를 최적화하고 있다.

기계 학습 단계
머신러닝 모델을 구축하기 위해 우리의 프로젝트는 훈련과 실험의 두 가지 주요 단계를 따라야 한다. 훈련 단계에서는 기계 학습 모델에 잘 정의된 기능을 공급하는 것이 중요하기 때문에 기능 엔지니어링 작업이 필요하다. 모든 자료가 우리 프로젝트에 유용한 것은 아니다. 우리가 사용할 머신러닝 알고리즘을 선택한 후 선택한 데이터로 공급한다. 교육 후, 우리는 많은 평가 지표를 바탕으로 모델을 평가하기 위해 모델을 시험하거나 소위 경험에 넣어야 한다.
시스템 학습 평가 메트릭
기계 학습 모델을 구축하는 것은 방법론적인 과정이다. 따라서, 우리의 기계 학습 모델 성능을 테스트하기 위해서는 과학적 공식에 기초하여 잘 정의된 측정 기준을 사용해야 한다: 이 모든 공식들은 네 가지 매개변수를 필요로 한다: 거짓 양성, 참 양성, 거짓 음성 및 참 음성이다.

표기법
- tp = True Positive(참의 양성)
- fp = 잘못된 긍정
- tn = 참 음수
- fn = 거짓 음성
정밀
정밀도 또는 양의 예측 값(Positive Predictional Value)은 총 양의 분류 표본 수로 올바르게 분류된 양의 표본의 비율이다.단순히 발견된 샘플의 수가 적중된 것이다.

리콜
리콜 또는 True Positive Rate는 데이터 집합의 총 양의 표본 수에 따른 진정한 양의 분류 비율이다. 그것은 얼마나 많은 진정한 긍정이 발견되었는지를 나타낸다.
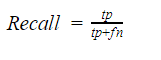
F-Score
F-Measurement의 F-점수는 정밀도와 리콜을 하나의 고조파 공식으로 결합한 척도다.
정확도
정확도는 총 표본 수에 따라 정확하게 분류된 표본의 비율이다. 이 방안은 그 자체로는 충분하지 않다. 왜냐하면 그것은 우리가 같은 반을 가질 때 사용되기 때문이다.

혼동 매트릭스
혼동 매트릭스는 분류 모델의 성능을 설명하는 데 자주 사용되는 표다.
기계 학습 파이선 프레임워크
프로그래밍 언어로서 우리는 많은 이유로 python을 사용했다. 먼저 다른 언어에 비해 자바와 C++보다 생산성과 유연성이 높다.thestateofai.com에 따르면 개발자의 78%가 개발 커뮤니티의 문서화 및 지원을 향상시키는 것을 의미하는 인공지능 프로젝트에서 python을 사용하고 있다고 한다. Python은 런타임과 복잡성 측면에서 외부적이고 쉽고 진보된 머신러닝 패키지를 출시하고 있다. 다음은 Machine 학습에서 가장 많이 사용되는 Python 라이브러리 중 하나이다.
• SciPy : 수학, 공학 분야에 일반적으로 사용된다.
• NumPy : 대형 다차원 배열과 선형대수를 조작하는 데 사용된다.
• MatplotLib : 혼동 매트릭스, Hitmaps, 선형 플롯을 포함한 우수한 데이터 시각화 기능 제공
• 텐서플로 : 구글의 머신 인텔리전스 연구 기관 내 구글 브레인 팀이 개발한 머신 인텔리전스 및 수치 계산을 위한 오픈 소스 라이브러리다.하나 이상의 CPU 및 GPU에 연산을 배포할 수 있다.
• 케라스 : 신경망 모델의 실험과 평가를 용이하게 하기 위해 텐서플로우 상단을 달리는 파이썬에서 작성된 오픈소스 신경망 라이브러리다.
• 테아노 : 신경망 모델의 실험과 평가를 용이하게 하기 위해 텐서플로우 상단에서 실행되는 파이썬에서 작성된 오픈소스 신경망 라이브러리다.
Python 라이브러리를 설치하려면 이 명령을 사용하여 pip install Package-Here
다음 그래프는 Favio Vazquez 특히 Deep Learning Framework에 의해 만들어진 일부 머신러닝 프레임워크의 비교를 보여준다.

잠깐, 하지만 딥러닝이란 무엇인가?
인공신경망과 딥러닝:
인공신경망의 주요 목표는 뇌가 어떻게 작용하는지를 모방하는 것이다.더 잘 이해하기 위해서 인간의 뇌가 실제로 어떻게 작용하는지 탐구해 봅시다.인간의 뇌는 듣기, 보기, 맛보기 등과 같은 다양한 작업을 수행하기 위해 많은 다양한 영역을 가진 매혹적인 복잡한 실체다. 만약 인간의 뇌가 여러 가지 일을 수행하기 위해 많은 영역을 사용한다면, 그래서 모든 영역이 특정한 알고리즘을 사용하여 논리적으로 작용한다. 예를 들어, 보는 알고리즘, 청력을 위한 알고리즘 등을...그렇지? 틀렸어! 뇌는 ONE 알고리즘을 사용하여 작동하고 있다. 이 가설은 "하나의 학습 알고리즘" 가설이라고 불린다. 인간의 뇌가 본질적으로 동일한 알고리즘을 사용하여 많은 다른 입력 방식을 이해한다는 증거가 있다. 자세한 내용은 시력에 대한 "입력"이 뇌의 청각 부분에 꽂혀 있고 청각 피질이 "보기"를 배우는 Ferret 실험을 점검한다. 뉴런 시스템을 구성하는 세포는 뉴런이라고 불린다.정보 전송은 전기화학 신호 전달을 이용하여 이루어지고 있으며, 전파는 뉴런 덴드라이트 덕분에 이루어진다.

머신러닝에서 인간의 뇌 뉴런을 비유하는 것을 퍼셉트론이라고 한다. 모든 입력 데이터가 합산되고 출력은 활성화 기능을 적용한다. 우리는 정보 관문으로서의 활성화 기능을 볼 수 있다.

PS: "셉트론과 인간 뉴런의 비유는 완전히 옳은 것은 아니다. 그것은 단지 어떻게 지각자가 작용하는지를 엿볼 때 사용된다. 인간의 마음은 인공신경망보다 훨씬 더 복잡하다. 비슷한 점이 거의 없지만 정신과 뉴럴 네트워크의 비교는 사실 맞지 않다."
사용되는 활성화 기능은 다음과 같다.
- 단계 기능 : 모든 출력 노드는 미리 정의된 임계값을 갖는다.
- Sigmoid 함수 : Sigmoid 함수는 가장 널리 사용되는 활성화 함수 중 하나이다.
- Tanh 함수 : Tanh 함수가 사용되는 또 다른 활성화 함수는 Tanh 함수다.
- ReLu 함수 : 정류된 선형 단위라고도 한다.출력 x가 양의 값이면 x를 주고 그렇지 않으면 0을 준다.

많은 연결된 수용체들이 세 부분으로 구성된 단순한 신경망을 구축한다. 입력 계층, 숨겨진 계층 및 출력 계층.숨겨진 계층은 신경망에서 통신간 역할을 하고 있거나 때로는 우리가 다층 수용체 네트워크라고 부르는 것을 하고 있다. 우리가 3개 이상의 숨겨진 층을 가지고 있다면, 우리는 딥 러닝과 딥 러닝 네트워크에 대해 이야기하고 있는 것이다.

데이터 과학자와 머신러닝 개업의 제이슨 브라운리 박사와 같은 딥러닝 전문가들에 따르면, 모든 딥러닝 모델은 다음 다섯 단계를 거쳐야 한다.
• 네트워크 정의: 이 단계에서는 계층을 정의해야 한다.케라스 덕분에 이 단계는 신경 네트워크를 시퀀스로 정의하고 레이어를 정의하려면 출력 수를 언급하면서 시퀀스 인스턴스를 생성하기만 하면 되기 때문에 쉽다.
• 네트워크 컴파일: 이제 평균 제곱 오차(mse)를 사용할 수 있는 모델을 평가하기 위해 스토크스틱 그라데이션 강하(sgd)와 손실 함수(손실 함수를 사용하여 적합도를 측정)와 같은 최적화 기법을 선택하는 등 네트워크를 컴파일해야 한다.
• 네트워크 피팅: 컴파일 단계에서 지정한 매개변수에 기초하여 이 단계 동안 백프로파게이션 알고리즘을 사용한다.
• 네트워크 평가 : 네트워크 장착 후 모델의 성능을 평가하기 위한 평가 작업이 필요하다
• 예측: 마지막으로 심층 학습 모델을 교육한 후 테스트데이터세트를 사용하여 새로운 멀웨어 샘플을 예측하는 데 사용할 수 있음
머신러닝(Machine Learning)이 포함된 침입 탐지 시스템
위험한 해커들은 보안 계층을 우회하고 탐지를 피하기 위해 매일 새로운 기술을 발명하고 있다.그러므로 이제 사이버 위협에 맞서기 위한 새로운 기술을 알아내야 할 때다. 침입 탐지 시스템은 침입과 악의적인 활동으로부터 방어하기 위해 현대 조직에서 큰 역할을 하는 장치나 소프트웨어의 집합이다.침입 탐지 시스템 범주는 크게 두 가지,
- HIDS(Host Based Intrusion Detection System): 엔터프라이즈 호스트에서 실행되며
- NIDS(Network Based Intrusion Detection System): 이들의 역할은 인바운드 및 아웃바운드 트래픽을 모니터링하여 네트워크 이상을 탐지하는 것이다.
탐지는 다음과 같은 두 가지 침입 탐지 기술을 사용하여 수행할 수 있다.

현대 조직은 매일 수천 개의 위협에 직면해 있다.그것이 고전적인 기술들이 그들을 방어하는 현명한 해결책이 될 수 없는 방법이다.많은 연구자들과 정보 보안 전문가들은 이 심각한 보안 문제를 해결하기 위해 새로운 개념, 프로토타입 또는 모델을 가지고 오고 있다.예를 들어, 이 그래프는 논의된 기계 학습 알고리즘을 포함한 다양한 침입 탐지 기술을 보여준다.

지금쯤이면 이전 섹션을 읽고 나면 기계학습 탐지 시스템을 구축할 수 있을 것이다. 첫 번째 단계 전에 논의한 바와 같이 데이터 처리.데이터 과학자가 머신러닝 모델을 교육하기 위해 사용하는 야생에서 공개적으로 사용할 수 있는 데이터셋이다.다음 사이트에서 다운로드하십시오.
- ADFA 침입 탐지 데이터셋: https://www.unsw.adfa.edu.au/australian-centre-for-cyber-security/cybersecurity/ADFA-IDS-Datasets/
- 공개적으로 사용 가능한 pcap 파일: http://www.netresec.com/?page=PcapFiles
- 사이버 연구 센터 - 데이터 세트: https://www.westpoint.edu/crc/SitePages/DataSets.aspx
- NSL-KDD 데이터 집합: https://github.com/defcom17/NSL_KDD
NSL-KDD는 침입 탐지 이상 징후 기반 모델에서 가장 많이 사용되는 데이터셋 중 하나이다.여기에는 다양한 공격 범주가 포함되어 있다. DoS, Probe, U2R 및 R2L.
KDD99 데이터 세트의 향상된 데이터 세트

작업할 기능을 선택하고 교육 및 경험을 위해 데이터 집합을 두 개의 하위 데이터베이스로 분할한 후(이들은 동일하지 않아야 함) 침입 탐지 기술 그래프에 표시된 기계 학습 알고리즘 중 하나를 선택하고 모델을 교육할 수 있다.마지막으로 교육 단계를 마치면 모델을 테스트하고 기계 학습 평가 지표를 기반으로 정확성을 점검해야 한다. 테스트된 모델 중 일부를 탐색하려면 "Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey" 연구 논문을 참조할 것을 권장한다.
머신러닝(machine learning)이나 인공지능(AI) 인정보보안(information security)의 약속에 대해 많은 얘기가 나오고 있지만, 반대편에서는 이에 대한 논쟁과 우려가 나오고 있다. 사이버 보안에서 머신러닝(Machine) 학습 약속에 대해 자세히 알아보려면 다음 웹 사이트를 통해 Thomas Dullien Talk: "머신 학습, 공격 및 자동화의 미래"를 시청하십시오.
요약
이 글은 정보보안 분야의 머신러닝에 대한 공정한 개요다.기초부터 기계학습 프로젝트 구축 기술 습득까지 모든 머신러닝 프로젝트에 필요한 기본 원리를 논의하였다.우리는 침입 탐지 시스템을 실제 사례 연구로 삼았다.
참조
- https://www.slideshare.net/idsecconf/jim-geovedi-machine-learning-for-cybersecurity
- https://blog.capterra.com/artificial-intelligence-in-cybersecurity/
How to build a Machine Learning Intrusion Detection system
Introduction
Machine learning techniques are changing our view of the world and they are impacting all aspects of our daily life. Thus machine learning is playing a huge role in information security. In this module you will not only explore the fundamentals behind machine learning techniques but you will dive into a hands-on experience to learn how to build real world Intrusion detection systems from scratch using cutting edge techniques, programming libraries and publicly available datasets.
This module will cover:
- Machine learning models
- The required steps to build a Machine learning project
- How to evaluate a machine learning Model
- Most useful Data Science and Machine learning libraries
- Artificial Neural Networks and Deep Learning
- Next Generation Intrusion detection systems using Machine learning Techniques.
Artificial intelligence
Artificial intelligence is the art of making computer programs to behave like a human and by behave i mean perceiving, learning, understanding and knowing. AI is involving many areas such as computer science, neuroscience, psychology and so on.

Machine Learning models
Machine learning is the study and the creation of algorithms that learn from given data and examples. It is a particular approach to artificial intelligence.Tom M. Mitchell (an american computer scientist ) defines machine learning as "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E" . In machine learning we have four major models; supervised, semi-supervised,unsupervised and reinforcement.
I. Supervised learning: if we have the Input and the Output variable then it is a supervised learning. In this case we only need to map the function between the inputs and the outputs. Supervised learning could be divided into two other sub-categories; Classification and regression: - Classification: when the output is a categorical variable - Regression: when the output variables are continuous values.
Let's discover some supervised learning algorithms:
- Naive Bayes: this classification algorithm is based on the the Bayes' theorem.

- Decision Trees: are machine learning algorithms that predict the possible outputs thanks to a tree-like graph,the entire data is represented as a root node and the final leafs are called Terminal Nodes.Dividable nodes are known as Decision Nodes.
- Support Vector Machines: are binary classifiers used to identify a separating hyper-plane of data that are represented in a multi-dimensional space.Thus, that hyper-plane is not necessary a simple line.

II. Semi-supervised: this model is not fully supervised while it contains both labeled and unlabeled data. This model is used generally to improve the learning accuracy. - Unsupervised: If we don't have information about the output variables then it is unsupervised learning.The model is trained totally with unlabeled data.Clustering is one of the most well known unsupervised techniques.

III. Reinforcement: in this model the agent is being optimized based on the feedback from the environment (the reward)

Machine learning steps
In order to build a Machine learning model our project need to follow two major phases; training and experimenting. During the training phase a feature engineering operation is needed because it is critical to feed the machine learning model with a well defined features. Not all the data is useful in our project. After choosing the machine learning algorithm that we are going to use, we feed it by the chosen data. After training, we need to put the model into a test or what we call an experience to evaluate the model based on many evaluation metrics.
Machine learning evaluation metrics
Building a machine learning model is a methodological process. Thus, in order to test our machine learning model performance we need to use a well-defined metrics based on scientific formulas: all these formulas are needing four parameters; false positive, true positive, false negative and true negative.

Notation
- tp = True Positive
- fp = False Positive
- tn = True Negative
- fn = False Negative
Precision
Precision or Positive Predictive Value, is the ratio of the positive samples that are correctly classified by the the total number of positive classified samples.Simply it is the number of the found samples were correct hits.

Recall
Recall or True Positive Rate, is the ratio of true positive classifications by the total number of positive samples in the dataset. It represents how many of the true positives were found.

F-Score
F-Score of F-Measure, is a measure that combines precision and recall in a one harmonic formula
Accuracy
Accuracy is the ratio of the total correctly classified samples by the total number of samples. This measure is not sufficient by itself,because it is used when we have equal number of classes.

Confusion Matrix
Confusion matrix is is a table that is often used to describe the performance of a classification model.
Machine learning python frameworks
As a programming language we used python for many reasons. First comparing to other languages it is more productive and flexible than Java and C++.According to thestateofai.com 78% of developers are using python in their Artificial intelligence projects that means a better documentation and support from the development community. Python is coming with external, easy and advanced machine learning packages in terms of run-time and complexity. The following are some of the most used Python libraries in Machine learning:
• SciPy : it is used for mathematics and engineering field in general
• NumPy : it is used to manipulate large multi-dimensional arrays and linear algebra
• MatplotLib : it provides great data visualization capabilities including: Confusion Matrix,Hitmaps,linear plots
• Tensorflow : is an open-source library for machine intelligence and numerical computation developed by Google Brain Team within Google's Machine Intelligence research organization .You can deploy computation to one or more CPUs and GPUs.
• Keras : is an open-source neural network library written in Python running on top of TensorFlow to ease the experimentation and the evaluation of the neural networks model.
• Theano : is an open source neural network library written in Python running on top of TensorFlow to ease the experimentation and the evaluation of the neural networks model.
To install any Python library this command will do the job : pip install Package-Here
The following graph illustrates a comparison between some machine learning frameworks made by Favio Vázquez especially Deep learning frameworks

Wait, but what is Deep Learning?
Artificial Neural networks and Deep Learning:
The main goal of Artificial neural networks is to mimic how the brain works.To have a better understanding let's explore how a human brain actually works.Human brain is a fascinated complex entity with many different regions to perform various tasks like listening, seeing, tasting and so on. If the human brain is using many regions to perform multiple tasks so logically every region act using a specific algorithm for example an algorithm for seeing, an algorithm for hearing etc...Right? Wrong! The brain is working using ONE Algorithm. This hypothesis It is called The "one learning algorithm" hypothesis. There is some evidence that the human brain uses essentially the same algorithm to understand many different input modalities. For more information check Ferret experiments, in which the "input" for vision was plugged into auditory part of brain, and the auditory cortex learns to "see." The cell that compose the neuron system is called a neuron.The information transmission is happening using electrochemical signalling and propagation is done thanks to the neuron dendrites.

The analogy of the human brain neuron in machine learning is called a perceptron. All the input data is summed and the output applies an activation function. We can see activation functions as information gates.

PS: " The analogy between a perceptron and a human neuron is not totally correct. It is used just to give a glimpse about how a perceptron works. The human mind is so far more complicated than Artificial neural networks. There are few similarities but a comparison between the mind and Neural networks is not really correct."
There are many used activation functions:
- Step Function : Every output node have a predefined threshold value
- Sigmoid Function : Sigmoid functions are one of the most widely used activation functions
- Tanh Function : Another activation function used is the Tanh function
- ReLu Function : It is also called a rectified linear unit.It gives an output x if x is positive and 0 otherwise.

Many connected perceptrons build a simple neural network that consists of three parts: Input layer,hidden layer and an output layer.The hidden layer is playing the inter-communication role in the neural network or sometimes what what we call a Multi-layer perceptron network. If we have more than 3 hidden layers then we are talking about Deep Learning and Deep learning Networks.

According to the data scientist and deep learning experts like the machine learning practitioner Dr. Jason Brownlee; every deep learning model must go thru five steps:
• Network Definition: in this phase we need to define the layers.Thanks to Keras this step is easy because it defines neural networks as sequences and to define layers we just need to create a sequence instance with mentioning the number of outputs
• Network Compiling: Now we need to compile the network including choosing the optimizing technique like Stochastic Gradient Descent (sgd) and a Loss function (Loss function is used to measure the degree of fit) to evaluate the model we can use Mean Squared Error (mse)
• Network Fitting: a Back-Propagation algorithm is used during this step based on the parameters specified in the compiling step.
• Network Evaluation : After fitting the network an evaluation operation is needed to evaluate the performance of the model
• Prediction: Finally after training the deep learningmodel we now can use it to predict a new malware sample using a testingdataset
Intrusion detection systems with Machine learning
Dangerous hackers are inventing new techniques in a daily basis to bypass security layers and avoid detection.Thus it is time to figure out new techniques to defend against cyber threats. Intrusion detection systems are a set of devices or pieces of software that play a huge role in modern organizations to defend against intrusions and malicious activities.We have two major intrusion detection system categories:
- Host Based Intrusion Detection Systems (HIDS): they run on the enterprise hosts to
- Network Based Intrusion Detection Systems (NIDS): their role is to detect network anomalies by monitoring the inbound and outbound traffic.
The detection can be done using two intrusion detection techniques:
- Signature based detection technique: the traffic is compared against a database of signatures of known threats
- Anomaly-based intrusion technique: inspects the traffic based on the behavior of activities.

Modern organization are facing thousands of threats in a daily basis.That is way the classic techniques could not be a wise solution to defend against them.Many researchers and information security professionals are coming with new concepts,prototypes or models to try solving this serious security issues.For example this is graph shows the different intrusion detection techniques including the discussed machine learning algorithms

By now, after reading the previous sections we are able to build a Machine learning detection system. As discussed before the first step is Data processing.The are many publicly available datasets in the wild used by data scientist to train machine learning models.You can download some of them from here:
- The ADFA Intrusion Detection Datasets: https://www.unsw.adfa.edu.au/australian-centre-for-cyber-security/cybersecurity/ADFA-IDS-Datasets/
- Publicly available pcap files: http://www.netresec.com/?page=PcapFiles
- The Cyber Research Center - DataSets: https://www.westpoint.edu/crc/SitePages/DataSets.aspx
- The NSL-KDD dataset: https://github.com/defcom17/NSL_KDD
The NSL-KDD is one of the most used datasets in intrusion detection anomaly based models.It contains different attacks categories: DoS, Probe, U2R and R2L.
It is an enhanced dataset from the KDD99 dataset

After choosing the feature that you are going to work on and splitting the dataset into two sub-datasets for the training and the experience (They should not be the same) you can choose one of the machine learning algorithms represented in the graph of intrusion detection techniques and train your model.Finally when you finish the training phase it is time to put your model to the test and check its accuracy based on the machine learning evaluation metrics. To explore some of the tested models i recommend taking an eye on "Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey" research paper.
There are a lot of talks about the promise of machine learning or AI ininformation security but in the other side there is a debate and some concerns about it. To discover more about Machine learning promises in cyber security it is highly recommended to watch Thomas Dullien Talk : " Machine Learning, offense, and the future of automation" from here:
You can also download the presentation slides from this link: Presentation Slides
Summary
This article is a fair overview of machine learning in information security.We discussed the required fundamentals in every machine learning project starting from the fundamentals to gaining the skills to build a machine learning projects.We took intrusion detection systems as real world case study.
References
※ 출처 : Blue Teams Academy | www.blueteamsacademy.com/?fbclid=IwAR0h-Vz8PtKLuStF5NEb9niYf07zYmRm2FPEioOt8AG03o9rgbhiYDMRhj8
'OffSec' 카테고리의 다른 글
| [Blue Teams Academy] 모듈 23 - Azure Sentinel - Filebeat 및 Logstash로 이벤트 전송 (0) | 2021.03.19 |
|---|---|
| [Blue Teams Academy] 모듈 22 - Azure Sentinel - 프로세스 중공(T1055.012) 분석 (0) | 2021.03.19 |
| [Blue Teams Academy] 모듈 20 - "Atomic Red Team"을 사용한 Red Teaming 공격 시뮬레이션 (0) | 2021.03.19 |
| [Blue Teams Academy] 모듈 19 - 메모리 분석 수행 방법 (0) | 2021.03.19 |
| [Blue Teams Academy] 모듈 18 - Ghidra를 사용한 리버스 엔지니어링 시작 (0) | 2021.03.19 |




댓글